What it took to make loomcycle a first-class n8n citizen

@loomcycle/n8n-nodes-loomcycle is the new
community package you can install in any self-hosted n8n
instance to drop loomcycle in as a first-class workflow
participant - its agents become spawn-and-await steps, its
channels become publish-and-subscribe primitives, its
substrate (AgentDef / SkillDef / MCPServerDef) becomes
manageable from inside the editor, and - the bit that matters
most - its LLM gateway becomes the Chat Model for n8n's own
AI Agent node.
The package went from v1.0.0 (Saturday) to v1.2.0 (today, Monday) in four days. Most of the shipped work was visible from the start. One piece was not, and most of this post is about that one piece: the LangChain Tools Agent integration story, which took three patches and ended with a defence-in-depth synthetic tool-call-id at every wire boundary.
First, the workflow shape that the package makes possible.
The workflow shape
Here's a typical producer workflow. A chat message arrives, a Researcher Agent runs against it (loomcycle spawns the agent, owns the loop, returns when done), a memory entry is written, a channel publishes the result for downstream consumption:
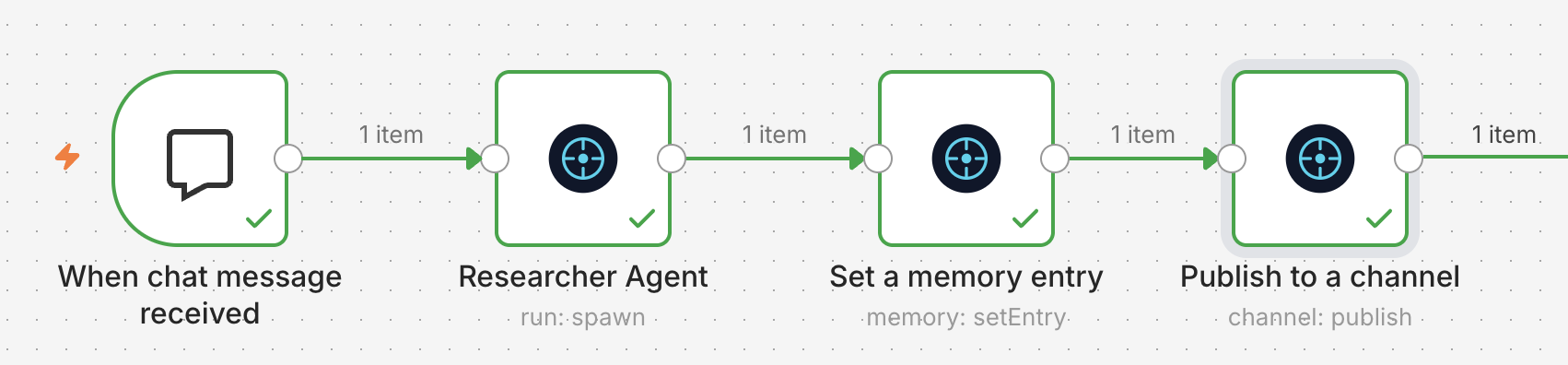
And here's the consumer workflow that picks up where the producer left off - a channel-message trigger fires when the publisher writes; the workflow reads the relevant memory entry and spawns the Editor Agent against it:
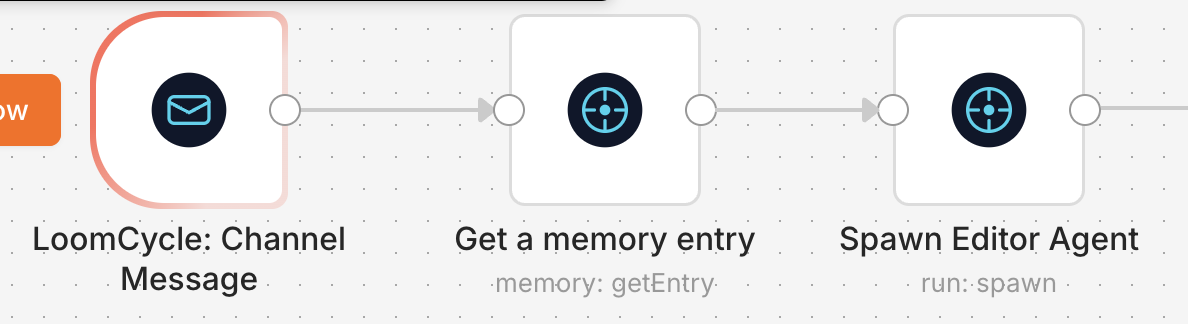
Two workflows, decoupled, talking via the loomcycle channel primitive plus shared memory. Neither workflow knows about the other; both know about the channel. If you've designed a queue-driven system before, this shape is familiar; the difference is that the agents on both sides of the queue are loomcycle agents with their own policies, tool surfaces, OTel traces, and per-tenant quotas - and the queue is a loomcycle channel, with the same auth and audit surface.
The two diagrams above were running off a development loomcycle while I was writing this post. The greens are real; so are the "1 item" edges. Here's the same workflow in motion:
Both workflows running end-to-end: chat message → researcher agent → memory write → channel publish → channel trigger fires → editor agent spawns against the stored memory entry. The loomcycle channel is the only coordination between them.
What ships in the package
Five categories of nodes - every loomcycle wire-surface operation that makes sense in an n8n editor is reachable.
- Action nodes (sub-phases 2.1 + 2.2). Three umbrella nodes: LoomCycle: Run (spawn / list / cancel agent runs), LoomCycle: Memory (full CRUD over the Memory tool's underlying store - get / list / setEntry / appendEntry / deleteEntry - with full text and vector search), and LoomCycle: Channel (publish, subscribe-via-trigger, list, CRUD over channels). Three substrate admin nodes: LoomCycle: AgentDef, LoomCycle: SkillDef, LoomCycle: MCPServerDef - verify / create / fork / retire / list / get against the substrate described in last week's post.
-
Trigger nodes (sub-phase 2.3). Two of
them: RunCompleted fires when an agent run
finishes; ChannelMessage fires when a message
is published to a watched channel. Both wired to
loomcycle's existing SSE stream
(
GET /v1/users/{user_id}/agents/stream), polished with the n8n trigger lifecycle - start / manual / stop methods, error recovery on disconnect, replay-from-last-event-id when n8n restarts. - Cluster sub-nodes (sub-phase 2.4). Four AI Agent cluster sub-nodes: LoomCycle Agent (spawn-and-await as a single tool call from inside an n8n AI Agent), and the three substrate sub-nodes again in cluster form. These plug into the standard n8n AI Agent's "Tools" slot so the agent can read / write loomcycle memory, publish to channels, and spawn loomcycle agents as tool calls.
-
Chat Model sub-node (v1.1.0). The
fifth cluster sub-node, and the most important one for
the broader story: LoomCycle Chat Model plugs
into n8n's AI Agent's Chat Model slot,
routing every model call the AI Agent makes through
POST /v1/_llm/chaton loomcycle's LLM Gateway. Existing n8n workflows that already use the AI Agent node keep working unchanged; the only thing that changes is which gateway sits behind the Chat Model dropdown. -
Example workflows (sub-phase 2.5).
Six JSON workflow exports living in
examples/. chat-to-channel, scheduled-research-publish, channel-listener-editor, agent-spawn-with-tools, substrate-bootstrap, and memory-rag-pipeline. Two of them are the workflows pictured above. All six round-trip cleanly through n8n's import; a CI cron hits a live loomcycle once a day to make sure the examples don't bit-rot.
The boring wins (worth saying out loud)
Three small things that took a patch each but mattered a lot:
The node picker. n8n 2.x changed how
community nodes appear in the workflow editor's node-picker
modal - nodes that declare categories: ["AI"]
on action nodes get filtered out of the general picker by
default. Our v1.0.0 action node was invisible until you
went hunting for it. v1.0.2 dropped the AI category from
the action node (kept it on the cluster sub-nodes, where
it belongs), and the picker found everything immediately.
Sounds trivial. Hours of "is this even installed?" before
we noticed.
The Agent dropdown. v1.0.0's
LoomCycle: Run → Spawn populated its Agent
dropdown by calling client.listUserAgents() -
a perfectly reasonable-sounding name for the wrong API.
That endpoint returns currently-running and
recently-completed agent instances for the
caller, not the agent library. So new agents that
hadn't been spawned yet didn't appear, and freshly-installed
loomcycles showed a dropdown reading "no running agents for
this user" - the empty-state placeholder, which several
operators read as "the loomcycle library is empty," when
really the library was fine and the n8n node was asking
the wrong question. v1.0.3 swapped to
client.listLibraryAgents() (new in
@loomcycle/client 0.10.3, wrapping the
Library v2 envelope endpoint). Each dropdown option now
also carries a source-tag description showing whether
that agent is STATIC (yaml-baked) or DYNAMIC (substrate).
Cluster sub-node execute(). n8n's cluster
sub-nodes used in the AI Agent's Tools slot need an
execute() method, not just a connection-time
getTools() declaration. Without it, the AI
Agent picks them up at definition time, lists them as
tools, but throws when actually invoking them. v1.0.4
added execute() to all four cluster sub-nodes.
The CI test that would have caught this earlier had to
learn how to type makeExecuteContext.inputJson
as IDataObject to satisfy n8n's index
signature, which is a sentence I now sadly understand.
The Tools Agent saga: bindTools, RunnableBinding, _getType, and a synthetic id
The Chat Model sub-node - the v1.1.0 release that lets n8n's AI Agent put its model calls through loomcycle - was where everything got interesting. Plugging into n8n's AI Agent means plugging into LangChain's Tools Agent, because that's what n8n's AI Agent is using under the hood. And LangChain's Tools Agent has opinions.
v1.1.0: Chat Model sub-node lands. Wired
to POST /v1/_llm/chat. Streams SSE on the
way out. Implements the
BaseChatModel.invoke / _generate / _stream
interface from @langchain/core. Smoke test
passes (a simple "respond with 'pong'" prompt).
v1.1.1: First real test against an n8n
AI Agent with a bound tool. The agent runs but never
attempts a tool call. The model is fine; the tools are
in the prompt; the issue is that LangChain's Tools Agent
decided the model doesn't support tools and went
to a no-tools-fallback prompting strategy. Why? Because
our BaseChatModel didn't implement
bindTools(). The Tools Agent does a feature
probe on the model - "can I bind tools to you?"
- and if the method isn't present, it falls back to a
tool-less ReAct prompt. We implemented
bindTools(tools, kwargs); the agent now sees
tool support; the agent starts attempting tool calls.
v1.1.2: The tool calls go out but
every bindTools() invocation throws.
TypeError: this.bind is not a function.
The standard LangChain pattern for
bindTools() is to call
this.bind({ tools: kwargs.tools, ...kwargs })
to return a RunnableBinding that carries the tool
definitions forward. this.bind exists on
Runnable but not, apparently, on our chat
model's prototype chain at invocation time inside n8n's
module-loading environment (some combination of CommonJS
vs ESM and n8n's vendored
@langchain/core version did it; we never
fully nailed the root cause inside n8n). The fix: stop
relying on the this.bind lookup; construct
RunnableBinding directly:
// Don't:
return this.bind({ tools: ..., ...kwargs });
// Do:
return new RunnableBinding({
bound: this,
kwargs: { tools, ...kwargs },
config: {},
});That patch unblocks tool calls.
v1.1.3: Tool calls happen, but
after each tool call returns, the AI Agent
throws "Cannot read properties of undefined
(reading 'id')" from somewhere deep in LangChain's
message-shape detection. Spent a while on this. The
Tools Agent inspects each message in the running
conversation and routes them via shape detection -
this is a HumanMessage, this is an AIMessage, this
is a ToolMessage - and our streaming-tool-call
emission was producing message chunks whose shape did
not satisfy LangChain's detection. The proper way to
do detection in modern @langchain/core is
to read _getType() on the message instance:
we'd been relying on instanceof checks. Fixed the
streaming tool-call emit to emit instances with the
right _getType(); UX cleanup along the way
to flush partial JSON args at the right SSE event.
Tool-using flows go green for the first time end to
end.
v1.1.4: The fix didn't fully take on
the operator's deployment. The exact same path that was
green on our test n8n was rejecting messages with
"messages[].tool_call_id is required" on
theirs. Same code, different LangChain runtime. We dug
into @langchain/core and found this:
// @langchain/core/messages/ai.js:178
if (!id || parsedArgs === null || ...) {
throw new Error("Malformed tool call chunk args.");
}
// → the tool call goes into invalid_tool_calls, NOT tool_calls
When the model emits a tool-call chunk with an empty
id - which is allowed by some provider
streaming formats, and was a default for our gateway in
the simplest streaming code path - LangChain's chunk
assembler doesn't throw immediately; it shunts the chunk
into invalid_tool_calls. The Tools Agent
then runs the tool anyway, but produces a
ToolMessage reply with an empty
tool_call_id. That ToolMessage hits the
next round-trip; the gateway rejects it
(messages[].tool_call_id required); the
whole agent flow craters with a confusing error two
steps removed from the actual cause.
The fix: mint a synthetic tool_call_id at
every wire boundary where one would otherwise be empty.
Outbound (model → wire): if the provider omitted an id,
we set one before it leaves the Chat Model. Inbound
(wire → tools): if a ToolMessage arrives with an empty
id and there's an obviously corresponding tool call in
the previous turn, we pair them. Both directions; both
defended; tests at both seams. The bug stops being
possible regardless of which provider is on the other
end of the gateway. Hence "defence-in-depth synthetic
tool_call_id at every wire boundary."
The generalizable lesson, take two: when you're plugging into someone else's runtime that does shape-routing on messages, the shape requirements are stricter than the protocol documents. The protocol says "id is optional in this streaming chunk"; the runtime's downstream assembler says "I'll silently route this to a dead path if id is absent." Both statements are true. The correct response is to make the id always-present at every seam you control, even when the protocol says you don't have to.
v1.2.0: full Memory + Channel CRUD
v1.2.0 today rounds out the Memory and Channel action
nodes from "publish / subscribe / read" to full CRUD -
list, get, set, append, delete on memory entries; list,
get, create, update, delete on channels. The bottleneck
wasn't the n8n side: it was that
@loomcycle/client's typed adapter didn't
yet wrap all the substrate ops on the
/v1/users/{user_id}/memory and
/v1/users/{user_id}/channels surfaces.
Adapter v0.11.5 added the wrappers; the n8n nodes
picked them up.
The reason to ship full CRUD as a unified release rather than dribble it out: the moment an operator can do spawn an agent, write a memory entry, subscribe to a channel, they reasonably expect to also be able to list the memory entries, delete the obsolete ones, and edit a channel's retention. Half-CRUD is a UX dead-end. Either the workflow author can manage the data or they cannot; "partially manage" is a footgun.
Installing it
In your self-hosted n8n instance, Settings → Community
Nodes → Install, paste in
@loomcycle/n8n-nodes-loomcycle. Restart n8n.
A new "LoomCycle" entry appears in the node picker. The
AI Agent's Chat Model dropdown gains a "LoomCycle Chat
Model" option. The AI Agent's Tools section gains four
LoomCycle cluster nodes.
Credentials: one n8n credential of type "LoomCycle API" - base URL, bearer token. Same credential covers every node in the package; same bearer token covers calls to every provider configured on the loomcycle's other side.
Examples: clone the package repo (github.com/denn-gubsky/n8n-nodes-loomcycle),
look in examples/, drag any of the six
JSON files into n8n's editor via Workflows →
Import from File.
What's next
Three things on the near horizon, in roughly priority order:
- Resource locator for the Agent dropdown. The current dropdown is a flat list. With a few dozen agents in a substrate it starts to need search and filtering - STATIC vs DYNAMIC, by tier, by tool family. n8n's resource-locator widget is the right primitive for this.
-
Streaming agent output to a webhook trigger.
Right now
RunCompletedfires after the agent finishes. Some workflows want progressive output - the agent emitted its first paragraph, kick off a downstream summarizer immediately. The SSE stream supports it; we need the n8n side to fan it out cleanly. - n8n cloud compatibility. Self-hosted is in scope today; n8n cloud's community-node policy is stricter, and we want the package on the verified list. Submission process is mid-flight.
Whole development arc, again: four days, six PRs against
n8n-nodes-loomcycle, three releases of
@loomcycle/client to keep the adapter
ahead of the n8n package, two minor loomcycle versions
(v0.11.0 - LLM Gateway, v0.11.5 - yaml-static channels)
shipped to round out the surfaces the n8n nodes needed
to plug into. The package is on npm under the
@loomcycle scope; the loomcycle binary is
on the GitHub releases page, the Homebrew tap, and as
a Docker image. The two halves talk over one bearer
token. The whole thing is Apache-2.0.
Companion writeups in this arc: Becoming OpenAI-shaped without becoming OpenAI (the LLM Gateway and shims this Chat Model sub-node plugs into), When the agent is in one container and its definition is in another (the substrate that lets the AgentDef / SkillDef / MCPServerDef admin nodes be useful from inside n8n's editor), and Scrubbing the model's incoming mail (the PostTool hook contract that any consumer - including an n8n-wrapped one - can register against the same loomcycle).